ナカバヤシとコラボのCamScannerアプリ、前回の記事 では意外なことにあまり使えなかったOCR検索。でも、せっかく機能がついているのだから、使えるのなら使いたい!
前回試したときは手書き文字だったからOCR機能の文字認識や検索がうまくいかなかっただけなのか。それとも、印刷された文字でも同じ結果なのか。それを調べるため、手書き文字と印刷文字とで比較してみました。
まずはサンプルにする文章を用意。
青空文庫の羅生門より、冒頭部分をお借りしました。
検索の邪魔になりそうなので、読み仮名なんかは最初に全部外しています。
ある日の暮方の事である。一人の下人が、羅生門の下で雨やみを待っていた。
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。
使ったフォントはWindowsでおなじみのMS明朝とMSゴシックです。最初は標準の10.5ptで撮影したのですが、iPhoneの画面で確認すると、ちょっと文字が小さかったのでどちらもフォントサイズを12ptにして撮り直しました。
それから手書きも用意。
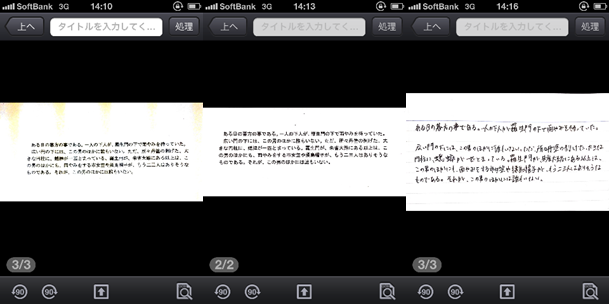
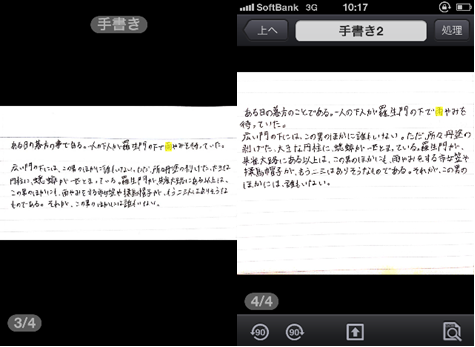
CamScanner撮影データ(左からMS明朝、MSゴシック、手書き文字)
iPhoneに取り込んだ時点では、MSゴシックが一番読みやすいかな?MS明朝だとちょっと文字が潰れているようですが、拡大してみると意外と大丈夫そう。
手書きの文字も罫線がなくなると結構見やすいです。いつもより綺麗めに書いたつもりだし、これならOCR検索も期待できそう!
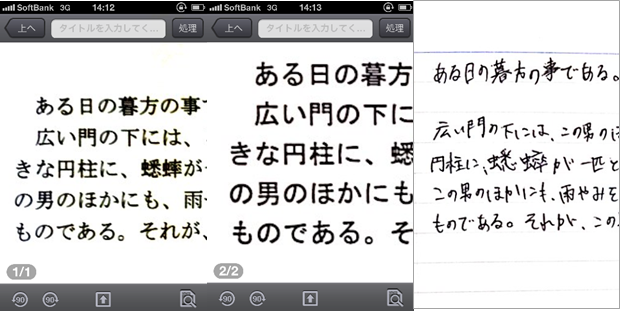
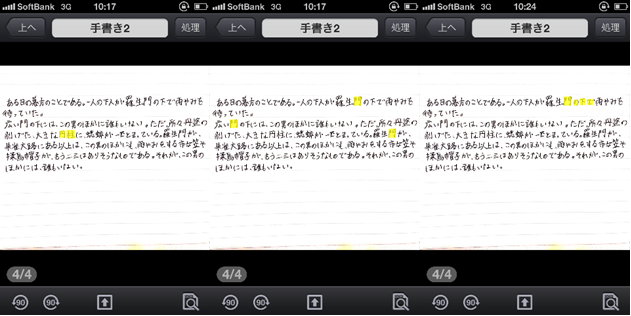
CamScanner撮影データ拡大(左からMS明朝、MSゴシック、手書き文字)
ということで、早速CamScanner で取り込んだ画像をOCRで文字認識します。
うーん……この文字認識の時に、手書きだけちょっと挙動不審というか、MSゴシックやMS明朝に比べて認識が遅い…?気がしました。
まあでも、一応OCRでの認識はできたということなので、大丈夫だと信じていよいよ検索をかけてみます!!
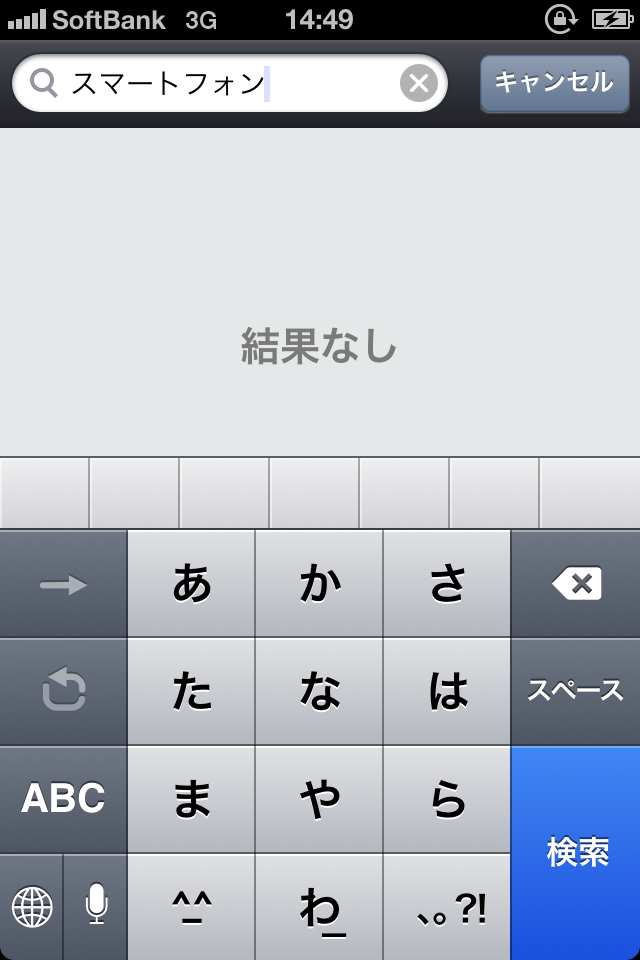
まずは、冒頭部分の「ある日の暮方の事である」を検索。
前回の「スマートフォン」でもそうだったけどあまり長い文字は無理なのかなーと思っていたら、ちゃんと検索できています!
が、検索されたのは印刷されたMS明朝とMSゴシックのみ。
きっと検索されるはず!と信じていた手書き文字はどうやら検索されていないよう……。やっぱり検索にかける言葉が長すぎたのかな?
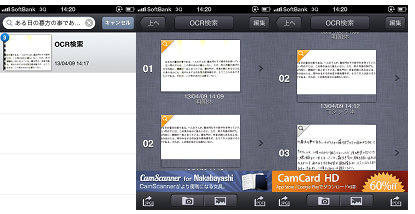
検索結果
仕方がないので検索文字列をちょっとずつ短くして試してみても、一向に検索にひっかかる様子がありません。
というか、一文字も検索にヒットしませんでした……(ノ∀`)
これでは、私の字がCamScannerに認識してもらえないくらい汚いとかそういう残念な結論になってしまうので、もう一度心持ち丁寧に同じ文章を書きなおしてみました。
何か繰り返し同じ文を書くって小学校の文字の練習みたいですね。
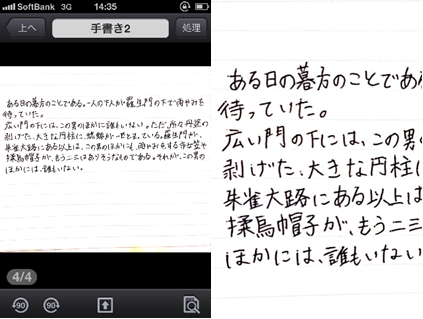
手書き文字を丁寧に書き直し

初めて手書き文字で検索結果が出ました
新たに書き直したものをOCRで文字認識させると、最初の時と同じようにちょっと挙動不審なのが気になるのですが、普段以上に綺麗になるように心がけて書いたのだから結果を残してほしい、と思いつつ再挑戦。
とりあえず、この状態で一応「あ」は認識してもらえたので最低限のラインはクリア……文字を丁寧に書けば、手書きでも認識はしてもらえるようです。
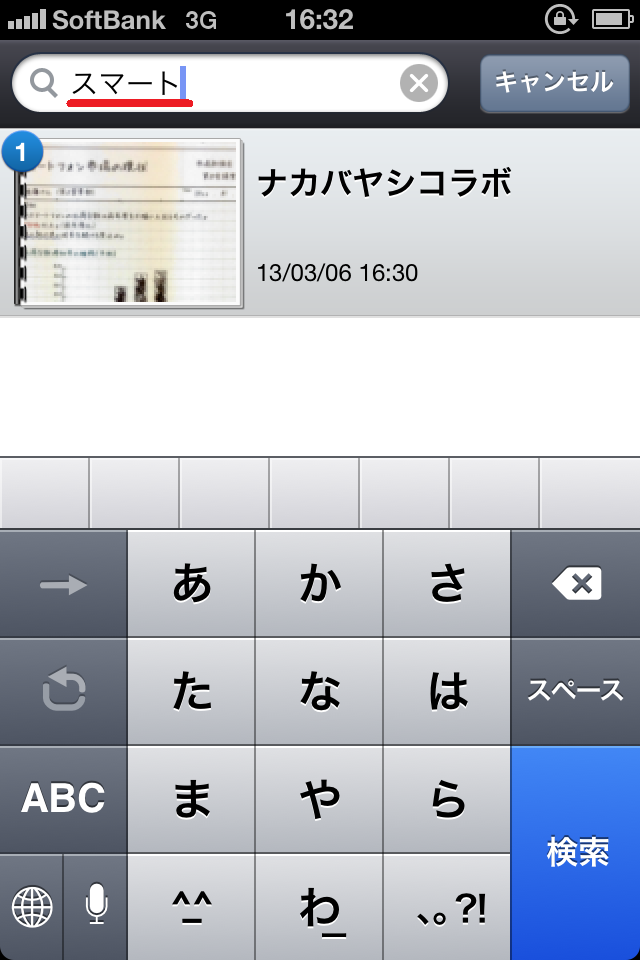
ちょっとほっとしたので、今度は短めの言葉として「ある日」を検索!
……結果は惨敗。せっかく綺麗に書いたつもりなのに、手書き文字は検索結果には全く出てきません。
これは、やっぱり単語は難しいのかな?人の目では普通に読める文字だと思うのですが、CamScannerに認識させるのは難しいよう。
それなら、もっと単純な形の文字ならどうだと「一人」に検索対象を変えてみたものの、結果は同じく無反応です。
これはさすがに認識してもらえているだろうと自信があったのですが、こうも無反応だとちょっとショックですね!
その後も、「ありそう」「それが」「広い」を検索してみたところ、やっぱり手書きは拾ってもらえませんでしたが、一文字の「雨」を検索したところ、最初に書いた手書き文字、二回目に書いた手書き文字の両方とも認識してもらえました!
雨の文字が検索にヒットしました
一文字くらいならいけるのかと「門」、また、簡単な漢字ならどうかと「円柱」を検索してみたら、これらの文字は認識されていました。
「門」はもう少しがんばれそうだったので検索にかける文字を増やして「門の下で」と入力してみたところ、無事検索に拾ってもらいました。
検索に成功した文字「門」「円柱」「門の下」
一方、MS明朝、MSゴシックはどの言葉も当たり前のように検索結果に出てきます。基本的に印刷したものは大体検索に拾われるようです。
ちなみに、検索結果にMS明朝・MSゴシックの書体による差はなかったです。
手書き文字でも検索にヒットするときがあることは分かりましたが、やっぱり手書き文字のOCR検索はちょっと使いづらそう。印刷の方は、手書きの検索で引っかからなかったものも全て検索できたので、OCR検索は使えそうです。
色々試してみた結論としては、人の手書きでは、文字を認識して検索にヒットすることもあるけど、印刷された文字に比べると著しくその確率が下がります。
会議や打ち合わせの時にとったメモをOCR検索で簡単に探せたらいいなー、と思っていたのだけど、丁寧に書いてこのヒット率の低さなので、実用性は大分低いと思います。
OCR検索を使うとしたら、対象は雑誌なんかの印刷された文字だけになるかも。